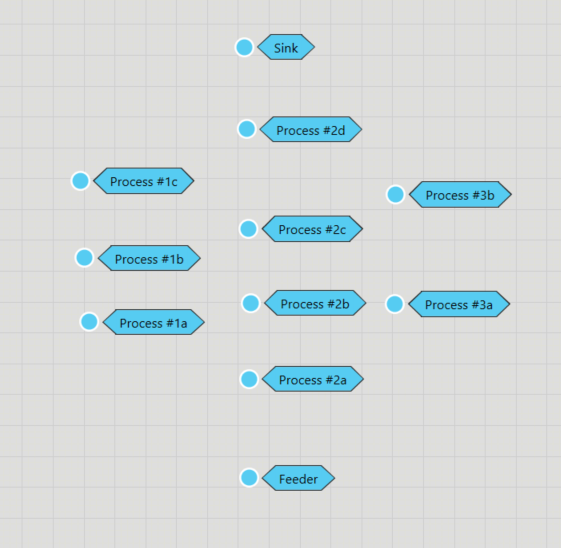
I have a process where I would like to feed 1 product type down 3 parallel lines. The distribution between the three lines is even. Each line has a different number of process nodes and branches accordingly:
As base principle, if your processes achieve the same operation on the product they should be the same process (have same name), so use same processes in all your branches if applicable.
You can also have alternative processes in same flow steps, but in the step sequence needs to be the same for all your parallel lines. If it is not, you would need to change the product type once a “line” is chosen for the product and have different sequences. You can then change the type to something else again before your lines merge.
It is also possible to essentially disregard the flow sequence per product using custom logic in processes with the Set next process and associated statements. Even more extensive manipulation and complete flow control can be done from the Python API such that maybe in extreme case you don’t have any flow sequence at all, yet the products go through processes using custom logic.
You don’t need a flow sequence if you create and manage the product feed objects yourself from Python script instead of using TransportOut statetements. This is because when creating a product feed you can specify arbitrary list of possible process ids where the product can get matched to go to.
There doesn’t even have to exist a process with that process id, just a product need that you can also create from Python script.
Also if you don’t need / want to use the product need and feed matching system, it is still possible to just use the transport system separately. You can create arbitrary valid vcTransportSolution, assign it to a vcProduct and then ask a vcTransportNode to begin transport. The transport system only requires you to have the transport nodes, links, and controllers configured, but doesn’t know / care anything about processes or flow sequences.
@TSy
Thank you very much for you fast and clear answer, I sincerely appreciate. However, I started using Visual Components like 3 months ago and I still have a lot to learn regarding the software.
I’m presently working on a project which focus on routing flexibility. I will read in details through your reply, also, I will ask you some specific question regarding my product. Your response is highly valued.
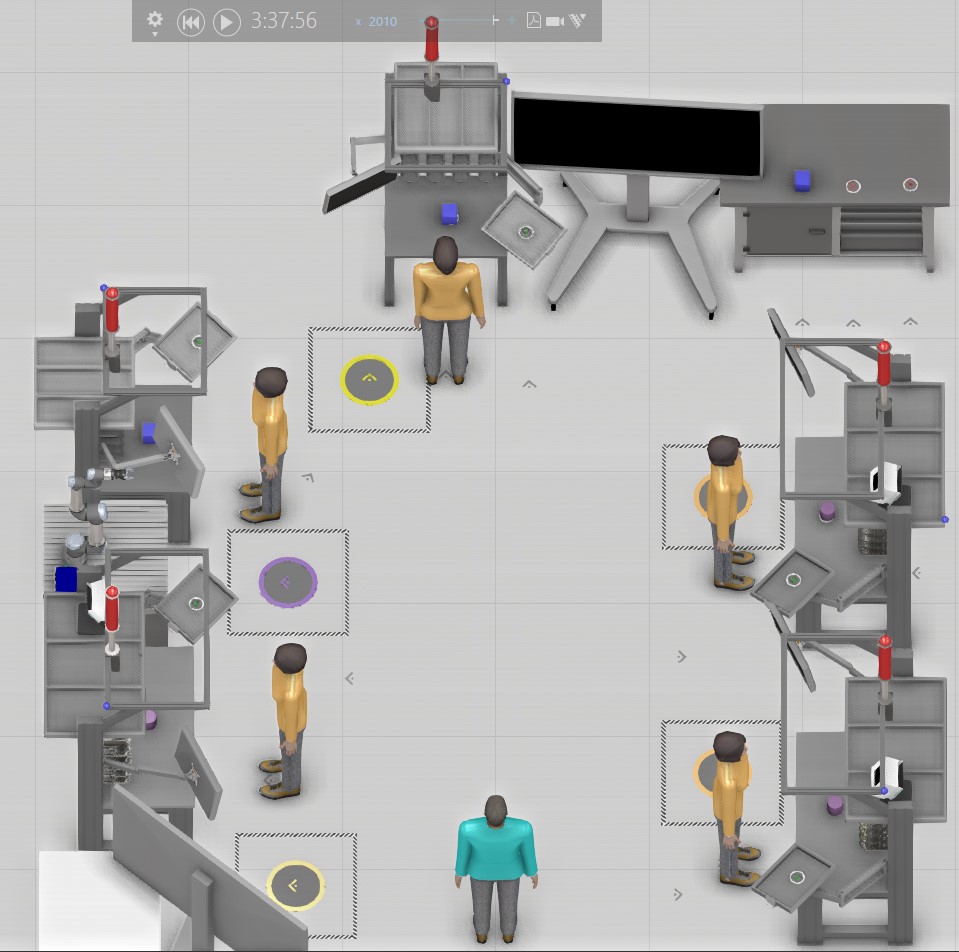
As shown in the model, each process node can perform 4 different processes, I have 2 product type in the model, and each work station is expected to perform 2 different processes on each product.
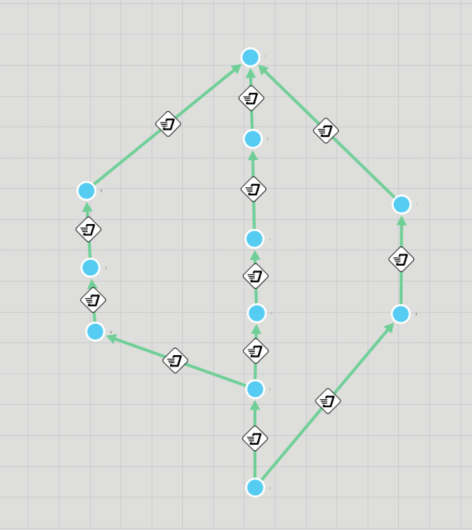
The process flow sequence for a product instance is:
But each of the Process step can be carried out on the machine which the product is allocated. I want to analyze 2 different cases.
Without Buffer.
With Buffer.
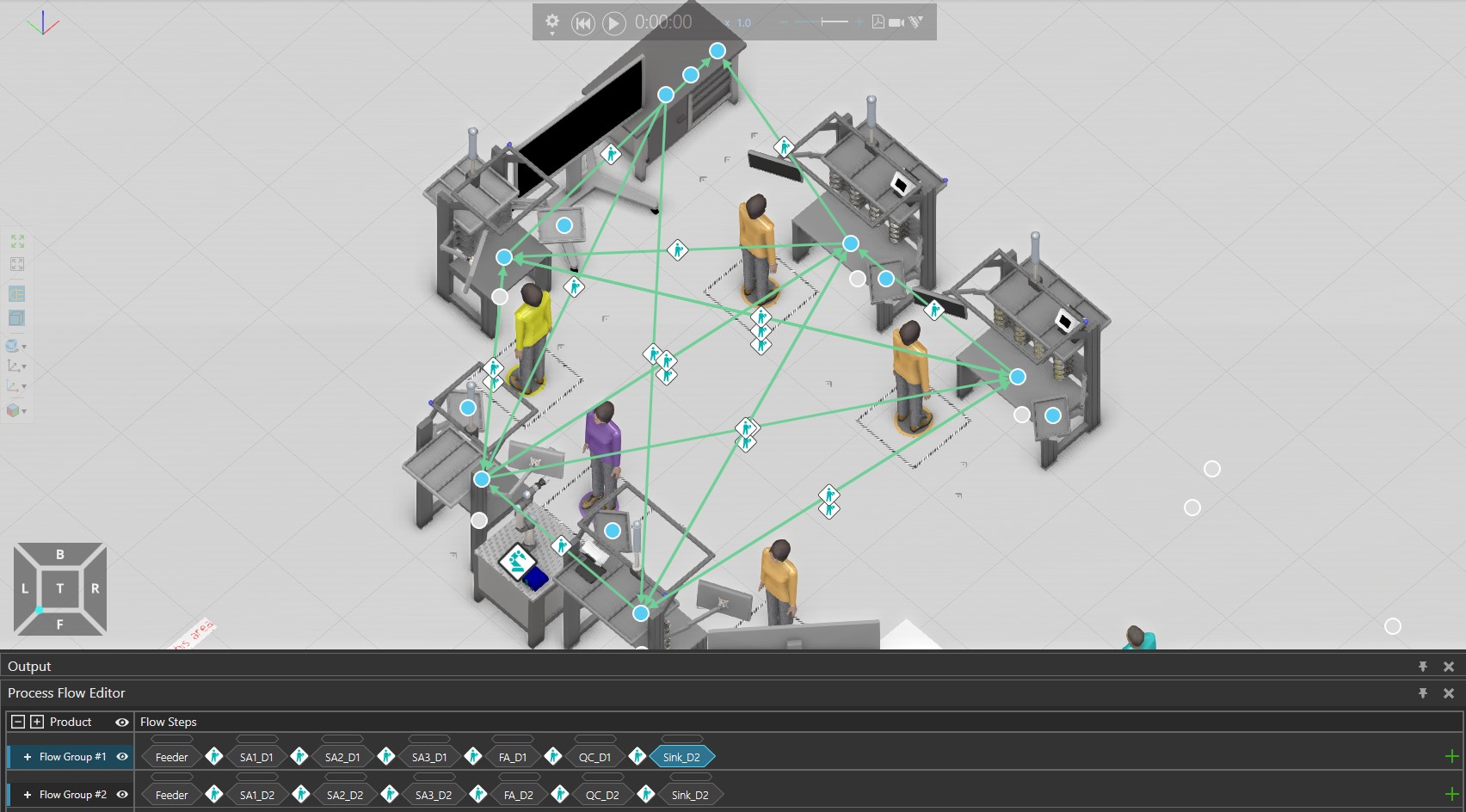
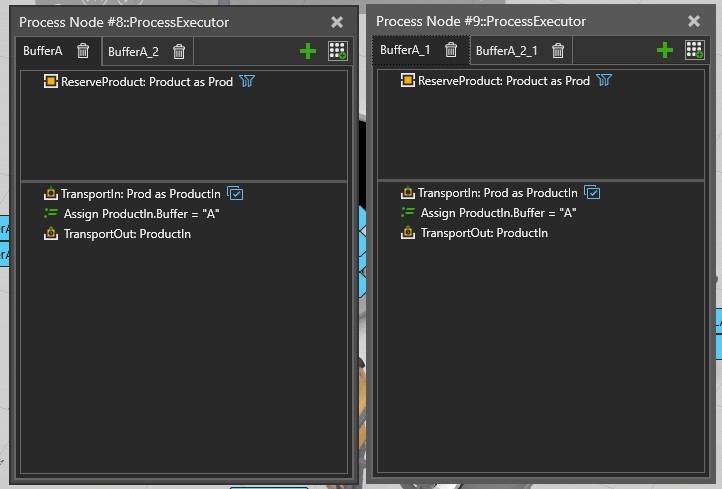
For the first case without Buffer, it is straight forward since I have assigned the same name to processes that performs the same function on the product. This is shown below:
Note: I created 2 flow groups because I have 2 product types with different processing times.
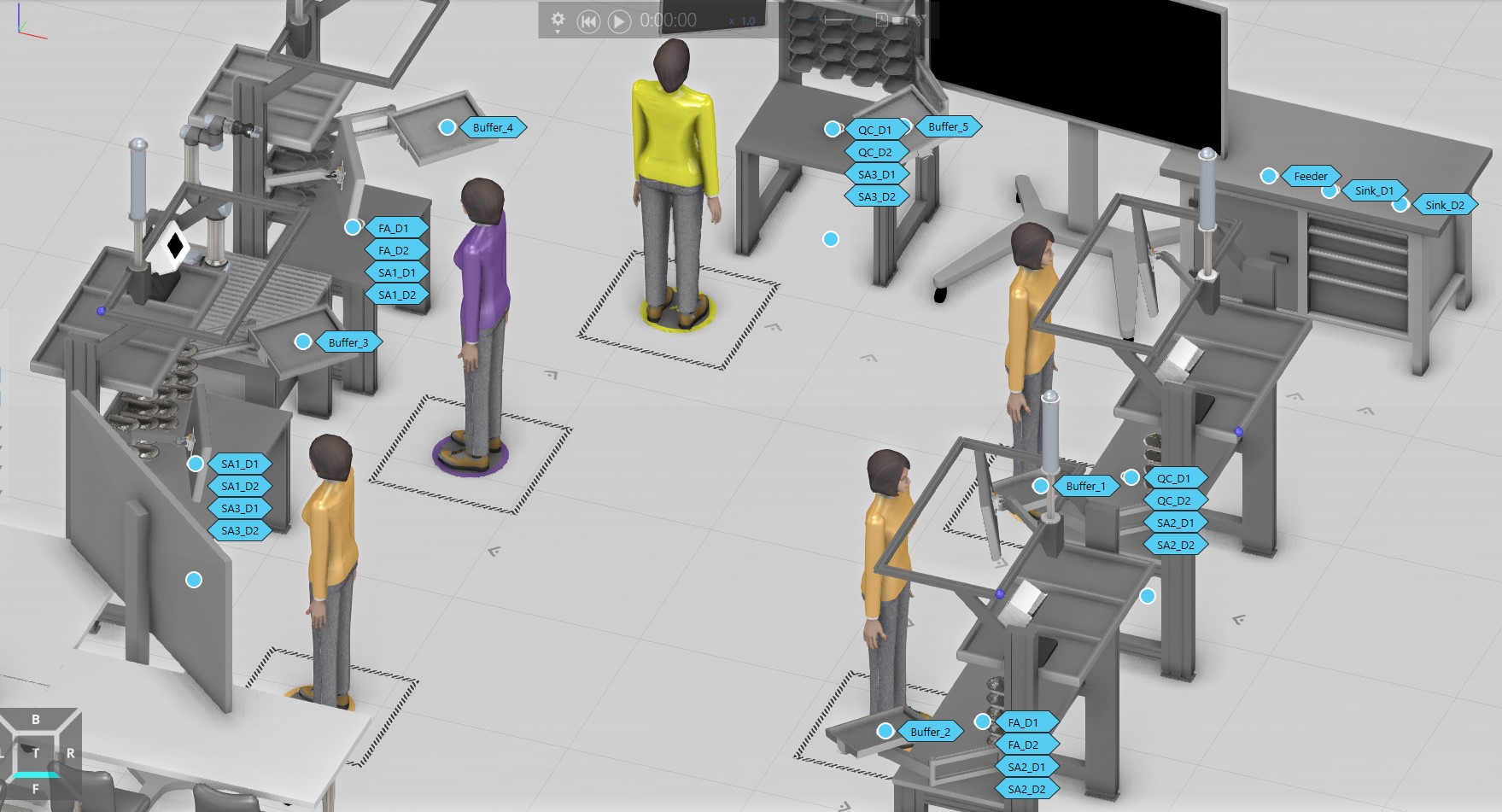
For the second case, I want each product instance to visit the associated buffer for the Work Station where the process would be carried out. This makes doing this a bit complicated by defining the process flow sequences for each flow group.
I have not make a good progress on this, any suggestion you give would be valuable for me.
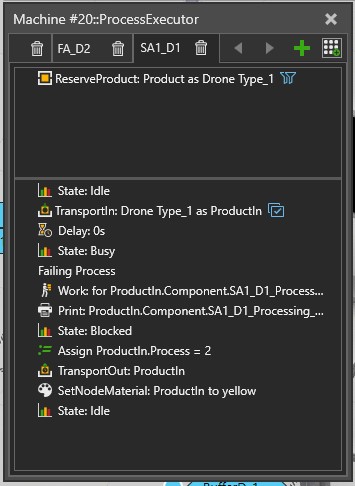
Lastly: For the model without Buffer, The model blocks when the amount of products in the model equal 5.
The layout used is also in the eCat → Layouts → Valve Milling Workareas
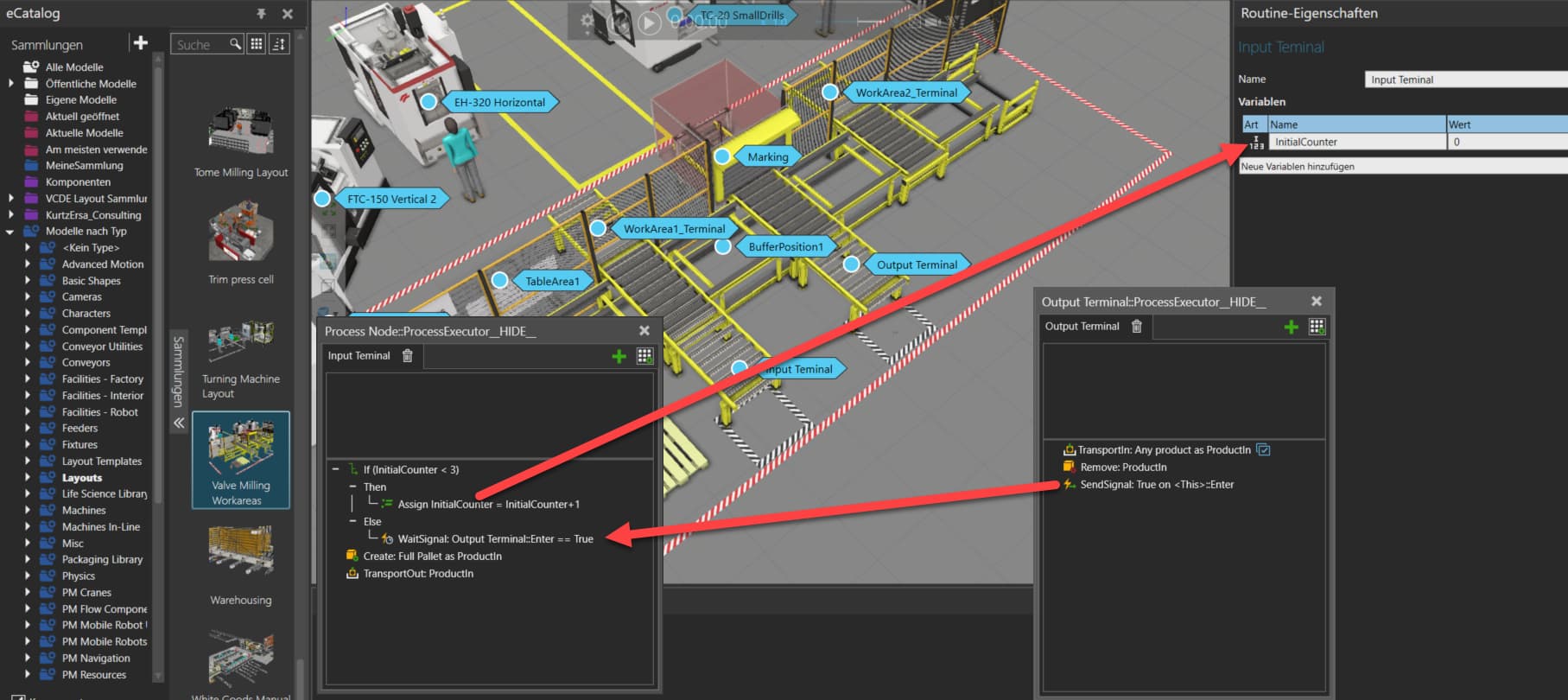
Instead of a Feeder Process, a standard Process Node was used with a Create statement.
It uses a variable “InitialCounter” to create 3 products at the begining, then waits for a signal from the sink/exit to create new products (there is a tool in the process tab to create signals in components). It enables to limit the number of products in the layout.
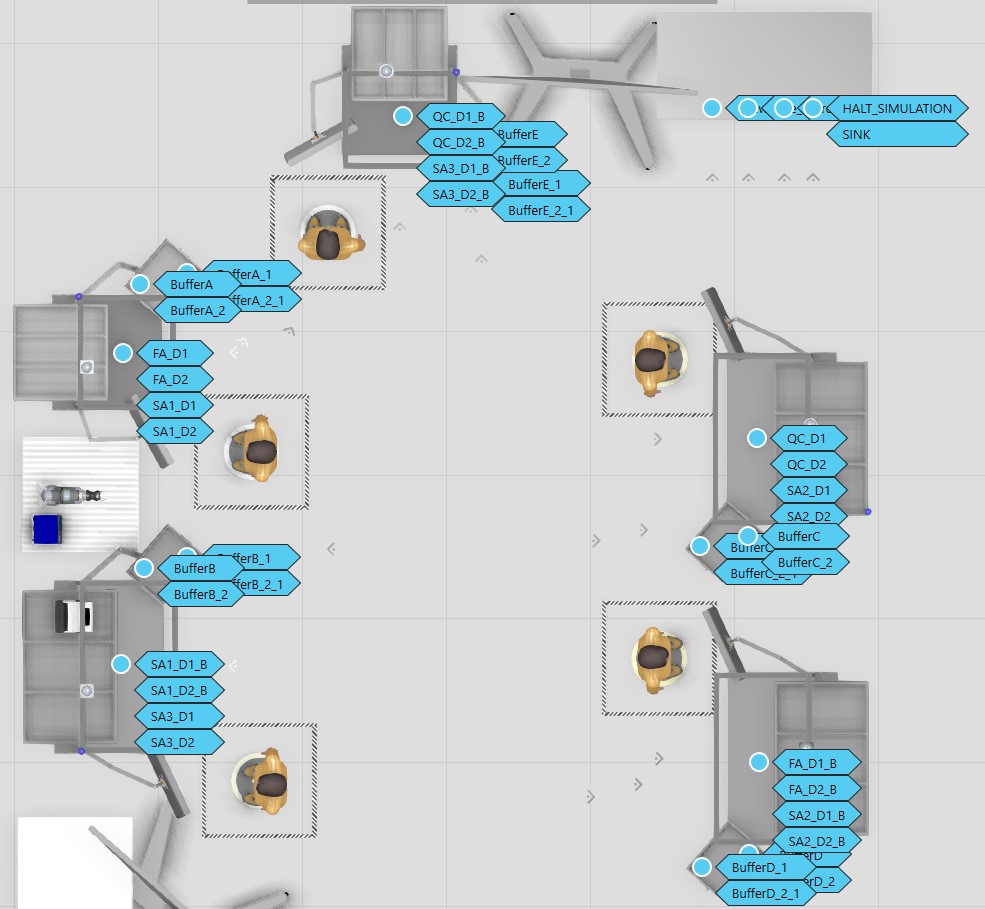
Hii @Tilma, please can you give some recommendation regarding my model. My aim for now is to increase the buffer capacity. I have built the model as shown below based based on your previous recommendations.
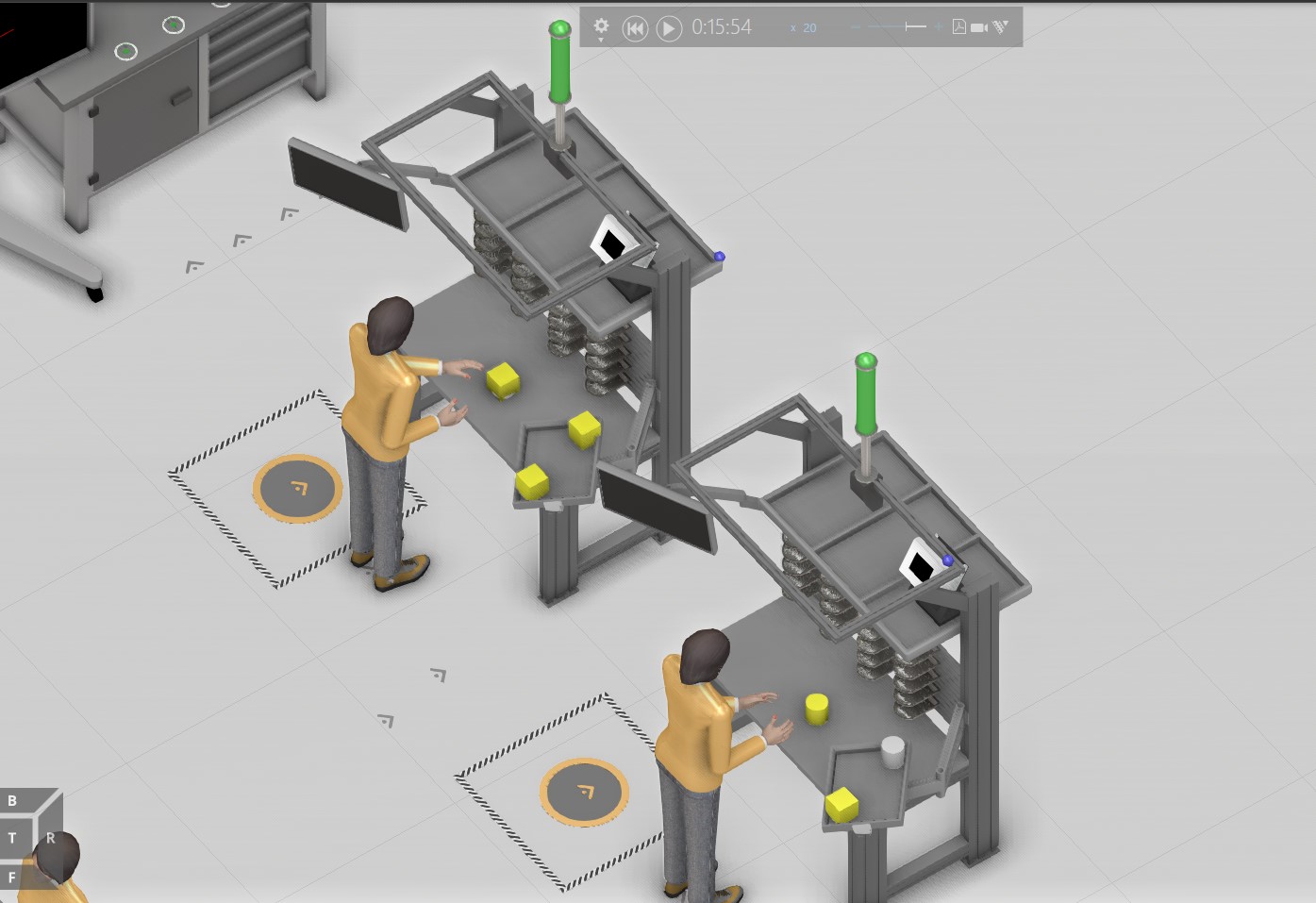
However, There is a problem with the model. It does not always transfer the products from the buffer into the process nodes based on First In First Out principle. If there are two products the same next process, It transfer from the buffer into the process node based on the FIFO principle as shown on the left side in screenshot below:
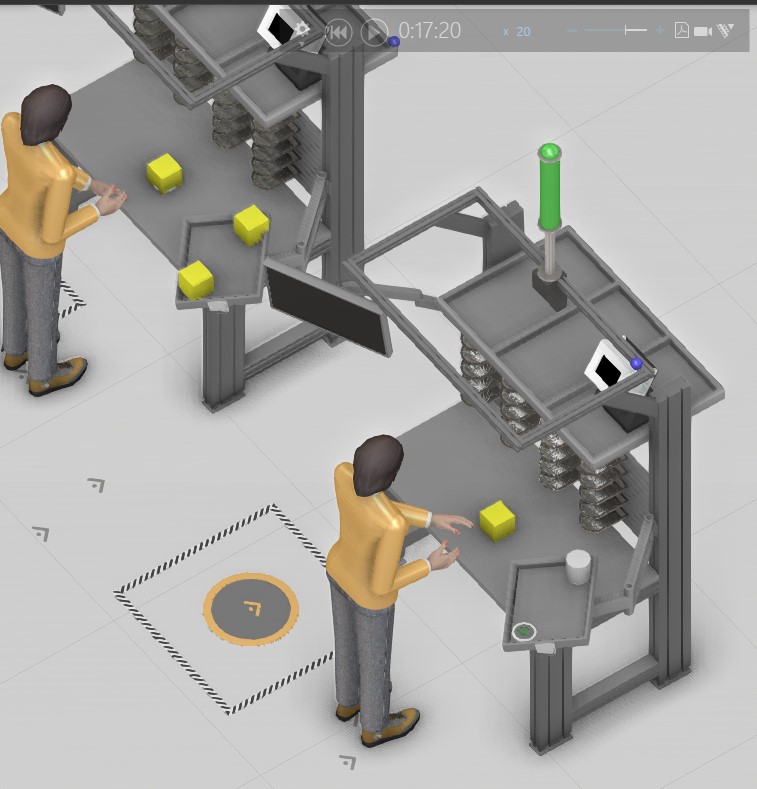
Similar color represent products with the same next work process. In this case the model works fine. However, when the there are two products with different next work process as demonstrated with different colors in the screenshot above. The yellow color represent a product which next process is sub-assembly 2, while the grey color represent a product which next work step is final assembly. The different shapes represent separate product variant.
The product with grey color should go next into the Process Node based on the FIFO principle, but the product with yellow color goes inside as shown below:
Can you suggest any recommendation to solve this problem or any other way to model the buffer in such a way that I can easily vary the buffer capacity.
Also, I have tried to use the Buffer process statement, but it does not work with the reserve product statement and the product get stucked in the buffer.
You probably need just one process with a Buffer statement if you want to have a buffer working in FIFO…
With products coming back in the same processes, it’s hard to not get some mix ups.
Maybe someone else has a better idea, but otherwise, you could try to divide the flow into several flow groups, so that you don’t get twice the same process in a flow…
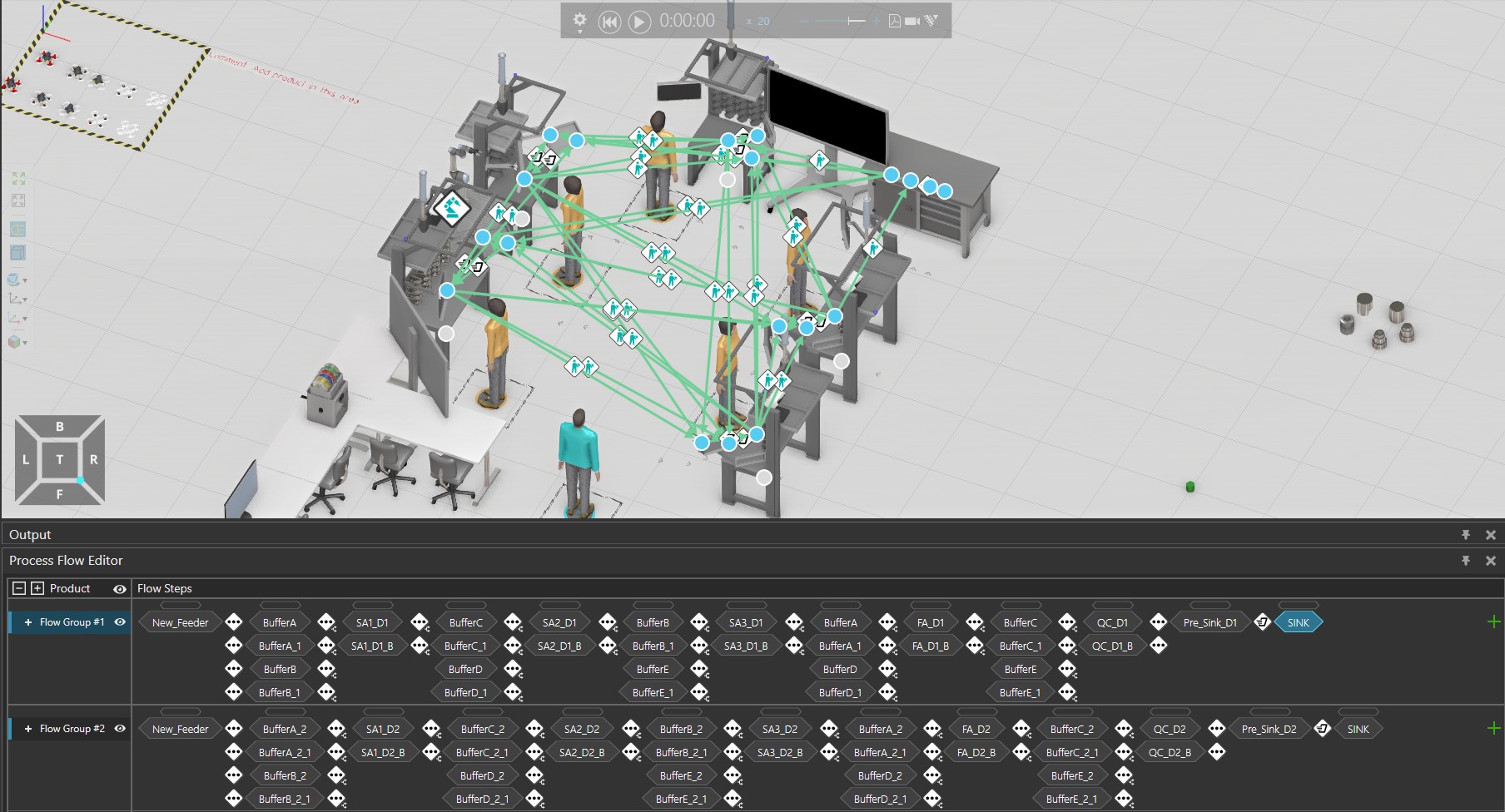
Here is an example, with 2 different product types : ReserveProduct_Layout_v2.vcmx (233.7 KB)
That way you can use the same process for different product types, by using a product property to define how long each product type is processed.
Thank you very much, @Tilma. I made it work to have two products waiting to be processed, but I did not use the buffer statement. I used to process nodes in series and some extra filters.
I will implement the method you present and see which one works better.
If someone else could provide some other insight, It would be helpful for me.